
Betreuung: Univ.-Prof. Dipl.-Ing. Dr. Bernhard Zagar
Sprache kann in zwei Arten von Lauten unterteilt werden, in Vokale und Konsonanten. Diese Unterscheidung wird in dieser Arbeit mithilfe eines Computers durchgeführt. Dafür sind folgende Zwischenschritte notwendig.
Eine geeignete Datenbank mit Sprachdateien wird verwendet, um daraus Features zu berechnen. Dazu müssen die Sprachaufnahmen in Zeitfenster unterteilt werden. Für jedes Fenster werden nahezu 100 verschiedene Werte berechnet, die bei der Differenzierung helfen. Alle der verwendeten Algorithmen kommen aus der Audio- und Signalverarbeitung.
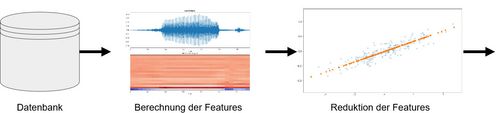 Abbildung 1: Erste Schritte, Verarbeitung der Daten
Abbildung 1: Erste Schritte, Verarbeitung der Daten
Für maschinelles Lernen ist es von Vorteil wenige, dafür aussagekräftige Werte zu haben. Aus diesem Grund wird im Anschluss die Anzahl an Features wieder reduziert. Das geschieht mit verschiedenen Algorithmen, wie beispielsweise der Hauptkomponentenanalyse.
Diese Daten werden genutzt, um eine künstliche Intelligenz zu trainieren. Durch das gesammelte Wissen ist diese im Stande, mit einer hohen Genauigkeit Vokale von Konsonanten zu trennen. Die Nachverarbeitung verbessert dieses Ergebnis noch, indem Ausreißer korrigiert werden.
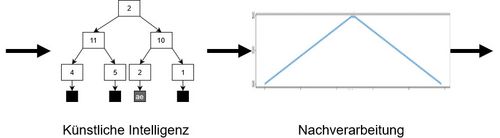
Anfangs werden in der Arbeit Grundlagen besprochen, die für das Verständnis der Algorithmen und der Datenbank wesentlich sind. Alle relevanten Sprachverarbeitunsverfahren und verwendeten Datenbanken werden im Anschluss ausführlich beschrieben. Da sich diese Arbeit auf die Signalverarbeitung fokussiert, wird das maschinelle Lernen weniger detailliert behandelt.
Schlagwörter: Vokalerkennung, KI, Formant
18. August 2020
Johannes Kepler Universität Linz
Altenberger Straße 69
4040 Linz, Österreich
 Zur JKU Startseite
Zur JKU Startseite
