Term: 3/2017 - 8/2020 (30 months)
Topic:
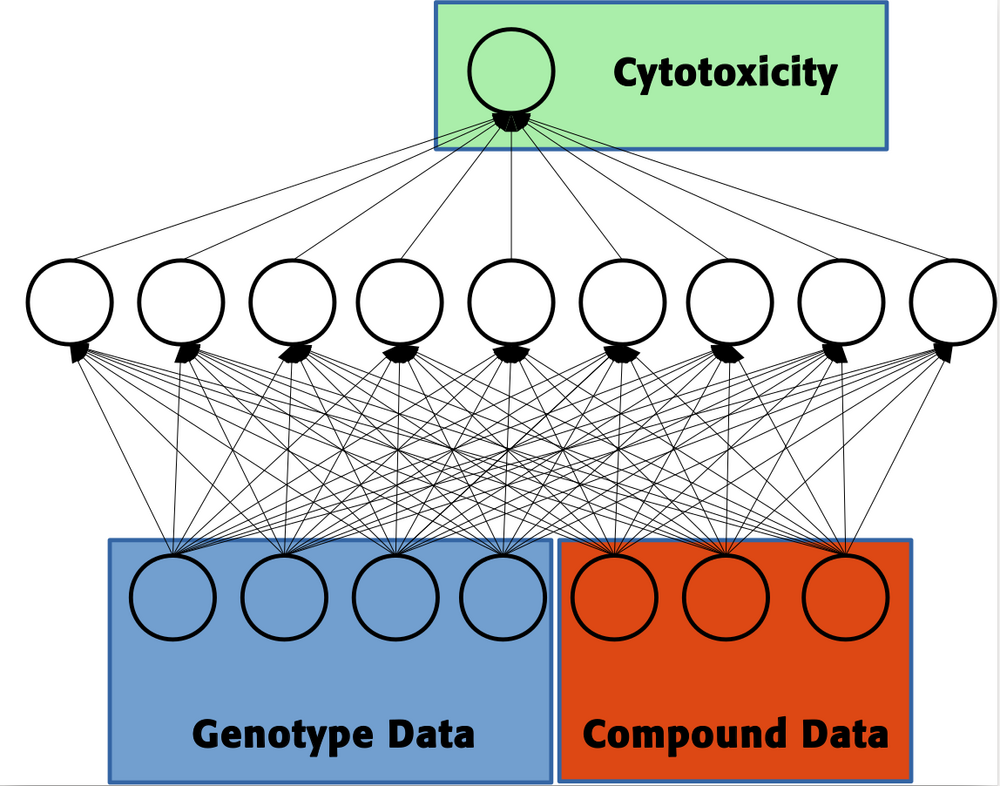
Testing the toxicity of a chemical compound before it is exposed to humans or animals reduces the damages done to the health of individuals. Therefore, time-and cost-intensive in-vitro and in-vivo biological tests have to be performed to determine a compound's toxicity. Recently, toxicological research has focused on computational methods as in-silico toxicity tests because they can determine the toxicity of many compounds in short time and at low costs. Ideally, these computational methods should reduce the number of necessary in-vitro and in- vivo toxicity tests or even replace biological experiments. In order to achieve this goal, the computational toxicity models have to be highly accurate. Therefore, both pharmaceutical companies and governmental organizations are interested in accurate computational methods for toxicity prediction to reduce or avoid biological testing and decrease animal testing. Currently, machine learning techniques, in particular Deep Learning, have pushed the accuracy of computational toxicity testing to a new level. For several toxic effects, the predictive performance of these Deep Learning models is so high that they can be considered “virtual assays†and indeed replace in-vitro testing. However, both in-vitro testing and computational methods for toxicity prediction perform well only for a single cell line or organism because they are based on measurements of this particular cell line or organism. This constitutes a large risk for humans, since the toxicity test might consider a compound as safe while it is harmful too many cell lines and organisms that were not tested. The toxic effect of a compound can vary by magnitudes between cell lines or individuals, which depends on the genetic features of the cell line or organism. Therefore, computational toxicity models have to take into account the genetic features of the cell line or organism: This new scientific field is termed 'toxicogenetics' and its aim is to develop models that predict the toxic effect of a compound on a particular organism represented by its genetic features. The successes at this task are relatively moderate, although genetic variation has to be the reason for the high variability of toxicity across cell lines of individuals. In this project, we are combining our expertise in genetics, toxicology and machine learning to largely improve toxicogenetics models. The aim of this project is to considerably increase the performance of computational methods for toxicogenetics predictions. This could enable to predict the toxic effect of a compound on a particular individual and ultimately reduce the damages done to humans by chemicals, decrease animal testing, and be a step towards personalized toxicology and medicine.
Johannes Kepler Universität Linz
Altenberger Straße 69
4040 Linz, Österreich
 Zur JKU Startseite
Zur JKU Startseite
